A few weeks ago, I found and reported CVE-2022-25636 - a heap out of bounds write in the Linux kernel.
The bug is exploitable to achieve kernel code execution (via ROP), giving full local privilege escalation, container escape, whatever you want.
In this post, I cover the entire process of finding and exploiting the bug (to as much of an extent as I did at least) - from initial “huh that looks weird” to a working LPE.
It’s a long post, but hopefully this will be useful to others (especially those newer to kernel exploitation) to get a feel for what my process was like.
Finally, if you’re just here for the exploit details and don’t want the backstory of me discovering it, feel free to skip head.
Bug Hunting
One night a few weeks back, I was bored. There were a few other projects I could have worked on,
but none of them seemed particularly interesting, so I decided to do some random (kernel) code review.
There have been a few notable bugs in the netfilter kernel subsystem that I’ve seen over the past few years
(perhaps most notably CVE-2021-22555), so I decided to start looking there.
It’s a relatively complex subsystem that’s widely available - the perfect target.
Aside: What is netfilter?
Netfilter, as the project’s website says, “enables packet filtering, network address [and port] translation (NA[P]T), packet logging, userspace packet queueing and other packet mangling.”
You’ve probably interacted with netfilter before without knowing about it!
Ever used iptables to block inbound traffic on a server, or configured a Linux box as a router with NAT?
All of that packet processing is done in the kernel by netfilter.
I’ve done a bunch of stuff with iptables in the past, but other than that I wasn’t familiar with anything else netfilter provided (and definitely didn’t know anything about how it worked),
so I clicked around on some files in the subsystem’s main source directory to try and get a lay of the land.
I started at the top by looking at a few of the (what seemed to be) protocol parsers. Parsing non-trivial data is always potentially error-prone, so it felt like a good place to start.
I ended up focusing on the parts of the code taking configuration input from userland (over a netlink socket), as while a bug in packet processing would be interesting,
the decoder would still have to be “activated” by some configuration from userland in the first place.
Editor’s note: perhaps it’s worth taking another look at these since syzkaller doesn’t show much of any coverage on these files so maybe there’s something lurking…
Anyways, after going through nf_conntrack_ftp.c and a few others without seeing much interesting,
I was scrolling through looking for other “types” of code and saw nf_dup_netdev.c.
I was actually just about to click on some other file when I saw that and thought “well maybe there could be some refcounting bug if something is duplicated” so I decided to look in there.
It’s quite a short file, but line 67
entry = &flow->rule->action.entries[ctx->num_actions++];
stood out to me for two particular reasons:
- It was incrementing
ctx->num_actions and using it as the index into an array without any bounds checking
- The index (
ctx->num_actions) and the array itself (flow->rule->action.entries) are struct members of two completely different variables, not obviously related. That is, the line is equivalent to a->b[x->y] which seems potentially more “suspicious” than a->b[a->c].
None of these reasons made this a definite bug (yet) of course, however it definitely “smelled” which prompted a bit more digging.
Is It a Bug?
I had a few immediate questions:
- What determines the size of the
action.entries array?
- How is
nft_fwd_dup_netdev_offload called? And what controls how many times it’s called?
- When/how is
ctx initialized?
At this point I also realized that this was in nft_fwd_dup_netdev_offload. Even if this bug was real, it may only be reachable on systems with Network Interface Cards (NICs) with support for packet processing offload, which are very rare (and very expensive).
It would still be a bug, but maybe not the most interesting bug in the world.
Pulling up the x-refs of nft_fwd_dup_netdev_offload showed it was called in a .offload handler of the dup and fwd nft_expr_types.
Looking at the references for the offload struct member (which is really not a pleasant experience in Elixir…), I found this use which answered all but one of the questions above:
ctx = kzalloc(sizeof(struct nft_offload_ctx), GFP_KERNEL);
...
while (nft_expr_more(rule, expr)) {
if (!expr->ops->offload) {
err = -EOPNOTSUPP;
goto err_out;
}
err = expr->ops->offload(ctx, flow, expr);
if (err < 0)
goto err_out;
expr = nft_expr_next(expr);
}
- How is
nft_fwd_dup_netdev_offload called?: It’s indirectly called as part of nft_flow_rule_create.
- What controls how many times
nft_fwd_dup_netdev_offload is called?: Offload handlers (and therefore nft_fwd_dup_netdev_offload for fwd/dup expressions) are called for every expression in the rule which has one. No other checks.
- When/how is
ctx initialized?: For each rule created, the context is zero-initialized and the same instance is passed to each offload handler.
More importantly than all of those however, the answer to the most interesting question was just above:
expr = nft_expr_first(rule);
while (nft_expr_more(rule, expr)) {
if (expr->ops->offload_flags & NFT_OFFLOAD_F_ACTION)
num_actions++;
expr = nft_expr_next(expr);
}
...
flow = nft_flow_rule_alloc(num_actions);
We see that for each expression in the rule, a num_actions counter is incremented only when the expression has a certain bit (NFT_OFFLOAD_F_ACTION) set in ops->offload_flags.
Quickly checking back at the definition for the dup and fwd expressions, neither of them have NFT_OFFLOAD_F_ACTION set.
In fact, there’s only one use of NFT_OFFLOAD_F_ACTION at all: in the immediate expression type (here).
At this point I was pretty confident there was a bug.
As far as I could tell, the only thing that could prevent it would be if there was some enforcement of having one immediate per dup/fwd rule.
Checking for Exploitability
Unfamiliar with how to “talk” to nftables, I searched around for some examples of what a nftables table/chain definition looks like and how to install it.
One mailing list post was particularly useful as it had everything needed, including how to set the offload flag which is required to reach the bug (because of this check).
table netdev filter_test {
chain ingress {
type filter hook ingress device eth0 priority 0; flags offload;
ip daddr 192.168.0.10 tcp dport 22 drop
}
}
With that sample in hand, I started playing around with nftables to see if/how the bug could be hit.
First, I setup a kprobe on flow_rule_alloc (responsible for creating our action.entries array) with a fetcharg to show the num_actions argument: sudo kprobe-perf -F 'p:flow_rule_alloc num_actions=%di:u32'.
This immediately failed because (at least on Ubuntu) nftables is a lazily loaded kernel module so the code wasn’t actually loaded yet. Oops.
After quickly running nft -a mailing_list.nft (which forced the kernel module to load even though the command itself failed), I could actually set the kprobe.
Running nft -a mailing_list.nft for real this time resulted in a kprobe hit (despite the rule installation failing):
$ sudo nft -f mailing_list.nft
a.nf:1:1-2: Error: Could not process rule: Operation not supported
table netdev x {
^^
$ sudo kprobe-perf 'p:flow_rule_alloc num_actions=%di:u32'
Tracing kprobe flow_rule_alloc. Ctrl-C to end.
nft-20137 [001] .... 1573655.306178: flow_rule_alloc: (flow_rule_alloc+0x0/0x60) num_actions=1
So flow_rule_alloc was indeed being hit even though the VM I was testing in definitely didn’t have a network device capable of hardware offload!
The system didn’t crash or anything so it seemed like the buggy behavior wasn’t getting hit yet, but this was good progress.
And it was at this point that I realized I had never changed the example from the mailing list to actually include a dup expression. Oops again.
After changing the rule to ip daddr 192.168.0.10 dup to eth0 though, my system annoyingly remained in a non-panicd state.
Before continuing, I also wanted to try running the nft commands after unshareing into a new user and network namespace (unshare -Urn) to see if it’s possible to reach this as an unprivileged user. Sure enough it was, making this bug potentially even more potent.
Back to the bug itself though: poking around through the nft man pages, I found you could pass -d netlink which ended up being incredibly useful as it showed the “disassembly” of the rule that was being sent to the kernel:
[ meta load protocol => reg 1 ]
[ cmp eq reg 1 0x00000008 ]
[ payload load 4b @ network header + 16 => reg 1 ]
[ cmp eq reg 1 0x0a00a8c0 ]
[ immediate reg 1 0x00000001 ]
[ dup sreg_dev 1 ]
From this, it’s apparent why the bug isn’t being triggered: the CLI generates an immediate expression before the dup (representing the device the packet should be duplicated to), so the accounting was “working”.
Is it possible to have a dup without a preceeding immediate?
I couldn’t find a way to have the CLI install a rule from this disassembled format (so couldn’t force it to generate dups with no immediates),
so it was time to go deeper and manually create the packets to send to the subsystem.
Golang Implementation
I have a love/hate relationship with Go, but that’s a blog for another time.
At the end of the day, it’s basically the only language that has a large community (and therefore a large selection of libraries) that’s low enough level to do what I need for this,
but also high enough level to not make me want to throw my computer out the window while I’m trying to get something to work.
So I started building a proof of concept in Go.
Conveniently, Google has a go nftables library which looked like a good starting point since I’d be able to manually construct the rule.
Unfortunately, it didn’t expose quite everything I needed (mainly around setting the offload flag) and by the time I discovered this, I was a few hours into building around it and really didn’t want to rewrite it in C.
I cobbled together some truely awful code which used reflection to overwrite the private array of messages to send, manually constructed the necessary chain creation message with the proper bit flipped, etc. etc. and another hour or so later I was back to where I started with the nft CLI.
I added another dup without an immediate before it, ran it and…
…
not much happened. It errored out with the normal “operation not permitted”, but nothing else. So at least it didn’t get rejected because of missing immediates which was good I guess?
Then, a few seconds later, kaboom. The kernel panicked and my shell was dead. We have a bug!
Now comes the fun part.
Exploitation
Analyzing what our bug actually provides us (with the help of pahole to get struct offsets), we see that there are 2 out of bounds writes:
entry = &flow->rule->action.entries[ctx->num_actions++];
entry->id = id;
entry->dev = dev;
- The write of
enum flow_action_id id immediately after the end of the array, writing the value 4 or 5 (depending on whether this is a fwd or dup) expression
- The write of
struct net_device *dev 24 bytes past the end of the array
As for the sizes of everything (on my Ubuntu test VM with a 5.13 kernel), the base flow_rule structure is 32 bytes and each additional entry in the array is 80 bytes. This means:
- If there are no immediates in our rule, the size of the rule allocation will be 32 and will be allocated in the kmalloc-32 slab
- One rule gives an allocation of size 112, landing in the kmalloc-128 slab
- Two rules gives an allocation of size 192, landing in the kmalloc-192 slab
- and so on
Focusing on the dev pointer write, the above allocation sizes means that the write will be either at offset 24 of the next 32- or 192-slab allocation, or at offset 8 of the next 128-slab allocation.
I manually hunted around through pahole’s output looking for any interesting structure which had a pointer at the necessary offset, but came up empty handed.
Everything that I found was either in a subsystem that required elevated privileges to access, in a subsystem that is “exotic” (probably not easily reachable), or in a subsystem which I felt was too flaky to try and land in (e.g. the scheduler).
Long story short, I put this aside and came back to it a couple days later with fresh eyes.
While reading through Alexander Popov’s writeup of another recent kernel bug looking for inspiration the thought occurred to me:
we have the ability to cause multiple of these out of bounds writes, not just one (since multiple dups can be put in a rule).
So in addition to hitting offset 8 of the next 128-slab allocation, we could also hit offset 88 of that allocation,
or offset 40 of the 2nd next allocation, or offset 120 of the 2nd next, or…
Having just read that writeup in which Alexander uses the security pointer (at offset 40) to land a kfree, the exploit path became obvious.
What we do is:
- Spray a bunch of System V message queue messages, causing the kernel to allocate a lot of
msg_msg structures of a controlled size. For now, we care about landing in the kmalloc-128 slab
- Free some of them
- Add the netlink rule, causing the
flow_rule allocation to hopefully land in one of the the just free’d heap slots
- Do our OOB write a total of 3 times (i.e. have 3
dups in our rule with no immediate), clobbering
- The
list_head.prev pointer (offset 8) of the next message on the heap
- Some random data (offset 88) in the contents of the next message on the heap
- The
security pointer (offset 40) of the 2nd next message on the heap
- Find and
msgrcv the 2nd next message, causing the kernel to kfree() the net_device (since it was a net_device pointer that was written)
- Allocate some more messages, but this time in the kmalloc-4k slab with the goal of landing in the
net_device that was just free’d
- Cause the kernel to do something on the device which would cause a function pointer in the (now controlled)
net_device.netdev_ops operations struct to be called, giving us code execution. Reading from /proc/net/dev is a simple answer to this (causing netdev_ops->ndo_get_stats64 to be called) which is what I ended up using.
This chain is incredibly nice. Just to highlight a few benefits:
- We know exactly which
msg_msg had its list_head.prev pointer clobbered (and is therefore unsafe to free) since we can MSG_COPY it out of the queue (which wont touch the next/prev pointers since it’s not actually removed) and look to see if the contents of the message have changed.
- In addition to telling us which message is “dangerous”, this also leaks the kernel heap pointer that we’re going to be landing in, making it trivial to start ROPing (more on this below).
- We also know exactly which message had its
security pointer overwritten. We could either add a 4th dup (and again look at message data after copying it), or we can look at the messages mtype after it’s copied out. Remember how 2 things are written out of bounds (4 or 5, and the pointer)? It just so happens that the 4 or 5 gets written over the message’s mtype (offset 16), so by checking if the mtype changed from whatever value was put in, we can tell if we have the right message.
By the end of the night (perhaps staying up a bit too late…), I had the first working proof of concept for this (in an ARM VM not x86, hence the different registers and whatnot).
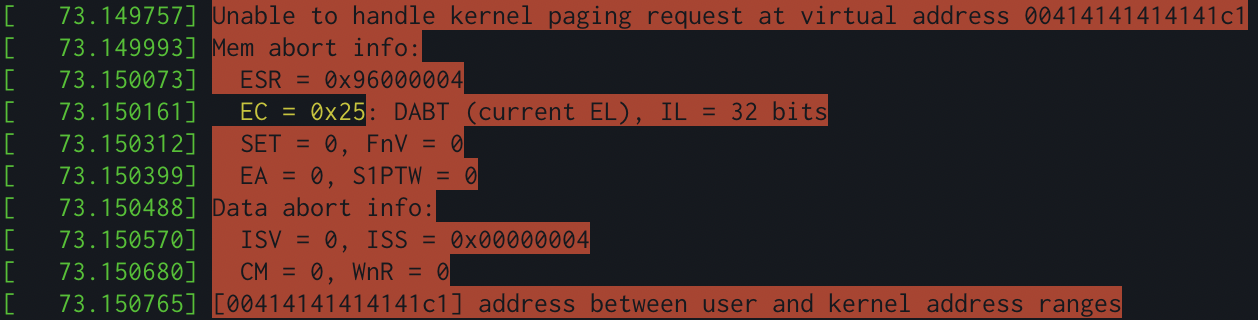
Success!
A few more hours of hacking on this though, and I hadn’t gotten much closer to code execution.
For some reason, the exploit was incredibly flaky (i.e. it had a very low success rate). I figured this was either because:
- The kernel freelist randomization was more potent than I thought against this
- All of the stuff the go runtime does in the background was messing with the kernel heap.
- Other things running on the system were causing sporadic
kmalloc-128 allocations, throwing off/using up the freelist
I tried changing everything to work out of the kmalloc-2048 slab (since all of the offset math still works out), but this didn’t seem to help at all.
At this point I probably should have spent some time with a kernel debugger, tracing exactly what was happening with the freelist, but I decided to go ahead and rewrite the exploit in C to see if that would help.
If nothing else, it’d probably make later stages of the exploit much easier to work with since I wouldn’t have to try and link in some other thing that the kernel could jump to as a final stage of the exploit.
Rewriting
Boy was this a nightmare. There is a C library for “nicely” working with nftables, however at the end of the day it’s C so nothing is really “nice.”
After many hours of staring at strace output of the netlink packets trying to figure out what I was missing in the C code, I eventually got back to where I was in goland.
If you’re interested, the code necessary to interface with nftables is available in the reproducer I posted to the oss-security mailing list.
But it wasn’t any more stable. Damn.
Another couple days of messing around (mainly trying to figure out if there was a specific order in which to free the initial messages to best get around freelist randomization), I got to a point where the exploit was ~30% successful which was good enough to proceed with.
It’s entirely possible I was missing something obviously broken in my exploit code, but if you have any ideas about something I could be missing kernel-side, please do drop me an email or DM - I would really like to know what’s going on.
Having spent enough time on this already, I decided to forgo making this into a full exploit. I just wanted to get my root shell and call it a day.
I disabled SMEP, SMAP, KPTI, and KASLR on my test VM, and put together a quick “callback” (getting me root and out of any container/namespace) which I could jump directly to from the kernel:
void *get_task(void) {
void *task;
asm volatile ("movq %%gs: 0x1fbc0, %0":"=r"(task));
return task;
}
void *elevate(void *dev, void *storage) {
void *c = ((void * (*)(int))(prepare_kernel_cred))(0);
((void (*)(void *))(commit_creds))(c);
void *current = get_task();
((void (*)(void *, void *))(switch_task_namespaces))(current, (void *)init_nsproxy);
return NULL;
}
And that’s basically it. Minus the whole “it only works 30% of the time,” the exploit was done, and I got my shell after a few attempts.
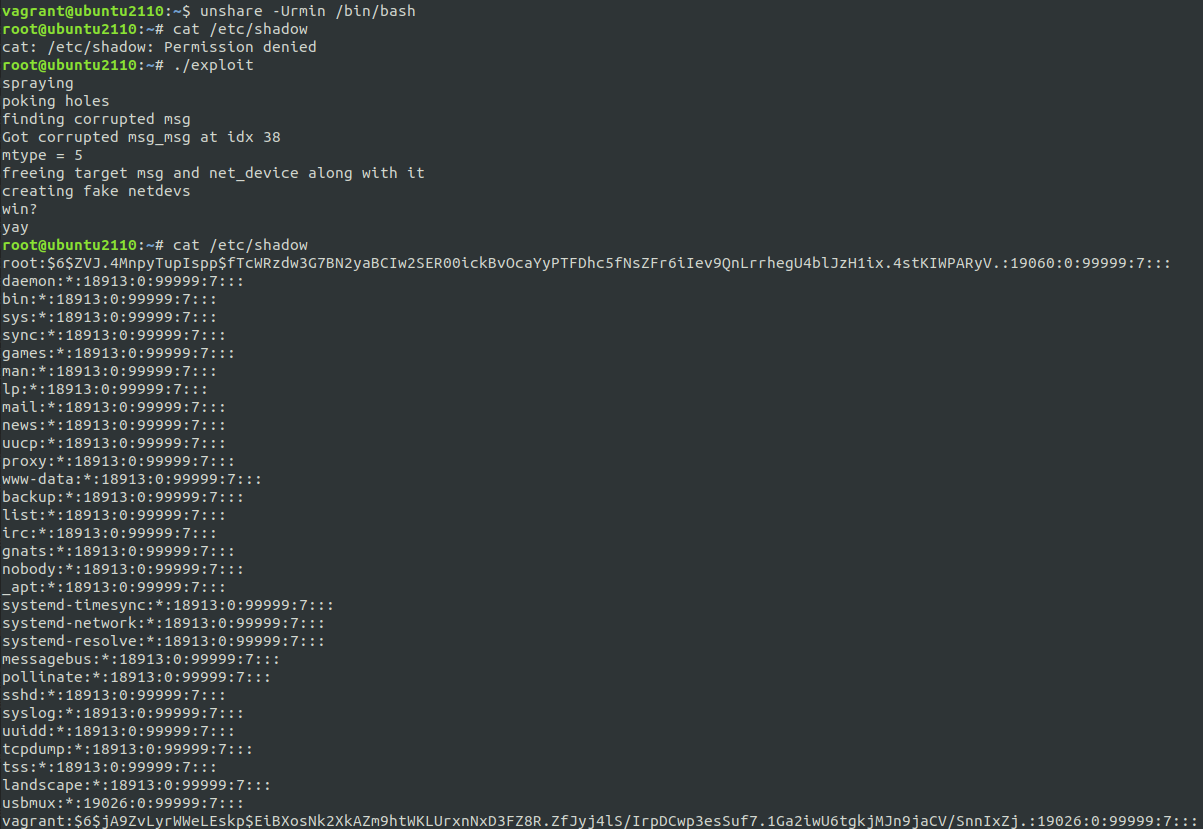
And before you go burning cycles trying to crack that password hash, it’s just vagrant :P
Sidenote: ROP
While I didn’t end up implementing it in my exploit, we’re in an amazing position to ROP (making SMEP/SMAP/KPTI a non-issue).
Since the kernel heap address of the net_device is leaked, we know where our message data is going to be in memory.
That pointer can then be used to compute an address for our fake netdev_ops (putting it somewhere else in our message),
and then when the kernel goes to call a function taken from that ops structure (with the net_device (/our message) as the first argument),
we can give it the address of a simple mov rsp, rdi; ret gadget to stack pivot on to our message.
From there, anything is possible.
The only thing missing is a KASLR leak, but that’s not much of a barrier :)
Code?
In the couple of weeks it took me to write up this blog post, @Bonfee already independently developed an exploit for the bug and published it!
I haven’t looked through the entirety of their implementation, but it seems to use a similar path to what I describe above. However, it also includes a full ROP chain and KASLR leak making it far more complete than mine. I’d recommend you check it out! https://github.com/Bonfee/CVE-2022-25636
Wrapping Up
This was a really fun bug to discover and work on. From start to end, it took just under a week to find, triage the bug, figure out how to hit it, and build the exploit.
While not novel, the OOB write primitive we get with it is also pretty interesting, and makes for quite a clean exploit as we’ve seen.
I hope you’ve enjoyed reading, and of course reach out with any questions you may have.
]]>


 Prompt: A mostly barren landscape with a few jagged peaks in the distance. The sky is a harsh, unforgiving blue, and the air is cold and dry.
Prompt: A mostly barren landscape with a few jagged peaks in the distance. The sky is a harsh, unforgiving blue, and the air is cold and dry. Prompt: This painting is of an abandoned building in the middle of a dark desert. The subject is an old, crumbling building surrounded by nothing but empty, scorched earth. The painting is dark and moody, with a erie, atmospheric feel to it.
Prompt: This painting is of an abandoned building in the middle of a dark desert. The subject is an old, crumbling building surrounded by nothing but empty, scorched earth. The painting is dark and moody, with a erie, atmospheric feel to it. Prompt: This painting depicts a bustling city street full of people and their belongings. The scene is brightly lit and colorful, and the buildings in the background are sharply silhouetted against the sky. The painting is undoubtedly impressionistic, with a loose, free style that allows the various elements to share the spotlight.
Prompt: This painting depicts a bustling city street full of people and their belongings. The scene is brightly lit and colorful, and the buildings in the background are sharply silhouetted against the sky. The painting is undoubtedly impressionistic, with a loose, free style that allows the various elements to share the spotlight. Prompt: This painting is of an abstract landscape with bright blues, greens, and oranges. It has a feeling of dynamism and energy, as if it is constantly moving. The style is impressionistic, with soft brush strokes and strong highlights.
Prompt: This painting is of an abstract landscape with bright blues, greens, and oranges. It has a feeling of dynamism and energy, as if it is constantly moving. The style is impressionistic, with soft brush strokes and strong highlights. Prompt: Salmon Run is an iconic painting by American painter Robert Henri. It depicts a panoramic view of the Columbia River, with salmon leaping upriver to spawn. The painting was commissioned by the Oregon Railroad and Navigation Company in 1914 as a celebration of the railroad’s 50th anniversary.
Prompt: Salmon Run is an iconic painting by American painter Robert Henri. It depicts a panoramic view of the Columbia River, with salmon leaping upriver to spawn. The painting was commissioned by the Oregon Railroad and Navigation Company in 1914 as a celebration of the railroad’s 50th anniversary.




{kind=link}